IT博文
MySQL 事务隔离级别详解
使用 docker compose 安装 tidb
架构师日记-如何写的一手好代码
生产事故-记一次特殊的OOM排查
Docker安装RabbitMQ——基于docker-compose工具
使用 docker-compose 部署单机 RabbitMQ
只需3步,即刻体验Oracle Database 23c
长达 1.7 万字的 explain 关键字指南!
Redis为什么能抗住10万并发?揭秘性能优越的背后原因
深度剖析Redis九种数据结构实现原理
【绩效季】遇到一个好领导有多重要,从被打差绩效到收获成长
为什么Redis不直接使用C语言的字符串?
Java阻塞队列中的异类,SynchronousQueue底层实现原理剖析
如何调整和优化 Go 程序的内存管理方式?
应用部署引起上游服务抖动问题分析及优化实践方案
Java 并发工具合集 JUC 大爆发!!!
卷起来!!这才是 MySQL 事务 & MVCC 的真相。
JDK8 到 JDK17 有哪些吸引人的新特性?
告别StringUtil:使用Java 11的全新String API优化你的代码
从JDK8飞升到JDK17,再到未来的JDK21
Java JMH Benchmark Tutorial
linux和macOS下top命令区别
Windows10关闭Hyper-V的三种方法
为什么应该选择 POSTGRES?
阿里云对象存储 OSS 限流超过阈值自动关闭【防破产,保平安】
Java高并发革命!JDK19新特性——虚拟线程(Virtual Threads)
“请不要在虚拟机中运行此程序”的解决方案
Spring中的循环依赖及解决
浅谈复杂业务系统的架构设计 | 京东云技术团队
面试题:聊聊TCP的粘包、拆包以及解决方案
操作日志记录实现方式
字节跳动技术团队-慢 SQL 分析与优化
Spring Boot 使用 AOP 防止重复提交
Controller层代码就该这么写,简洁又优雅!
SpringBoot 项目 + JWT 完成用户登录、注册、鉴权
重复提交不再是问题!SpringBoot自定义注解+AOP巧妙解决
SpringBoot 整合 ES 实现 CRUD 操作
SpringBoot 整合 ES 进行各种高级查询搜索
SpringBoot操作ES进行各种高级查询
SpringBoot整合ES查询
如何做架构设计? | 京东云技术团队
最值得推荐的五个VPN软件(便宜+好用+稳定),靠谱的V2ray梯子工具
我说MySQL每张表最好不超过2000万数据,面试官让我回去等通知?
vivo 自研鲁班分布式 ID 服务实践
使用自带zookeeper超简单安装kafka
推荐 6 个很牛的 IDEA 插件
喜马拉雅 Redis 与 Pika 缓存使用军规
「程序员转型技术管理」必修的 10 个能力提升方向
jdk17 下 netty 导致堆内存疯涨原因排查 | 京东云技术团队
如何优雅做好项目管理?
MySQL 到 TiDB:Hive Metastore 横向扩展之路
聊聊即将到来的 MySQL5.7 停服事件
Linux终端环境配置
微软 Edge 浏览器隐藏功能一览:多线程下载、IE 模式、阻止视频自动播放等
Hutool 中那些常用的工具类和实用方法
clash 内核删库?汇总目前常用的内核仓库和客户端
JDK11 升级 JDK17 最全实践干货来了 | 京东云技术团队
我是如何写一篇技术文的?
虚拟线程原理及性能分析
Java线程池实现原理及其在美团业务中的实践
Editplus和EmEditor配置一键编译java运行环境
用Spring Boot 3.2虚拟线程搭建静态文件服务器有多快?
SpringBoot中使用LocalDateTime踩坑记录 - 程序员偏安 - 博客园
程序员必备!10款实用便捷的Git可视化管理工具 - 追逐时光者 - 博客园
基于Netty开发轻量级RPC框架
开发Java应用时如何用好Log
复杂SQL治理实践 | 京东物流技术团队
火山引擎ByteHouse:分析型数据库如何设计并发控制?
多次崩了之后,阿里云终于改了
推荐程序员必知的四大神级学习网站
初探分布式链路追踪
新项目为什么决定用 JDK 17了
Java上进了,JDK21 要来了,并发编程再也不是噩梦了
mapstruct这么用,同事也开始模仿
再见RestTemplate,Spring 6.1新特性:RestClient 了解一下!
【MySQL】MySQL表设计的经验(建议收藏)
如何正确地理解应用架构并开发
解读工行专利CN112905176B
工商银行取得「基于 Spring Boot 的 web 系统后端实现方法及装置」专利
IDEA 2024.1:Spring支持增强、GitHub Action支持增强、更新HTTP Client等
TIOBE 2 月:Go 首次进入前十、“上古语言” COBOL 和 Fortran 排名飙升
Java 21 虚拟线程如何限流控制吞吐量
🎉 通用、灵活、高性能分布式 ID 生成器 | CosId 2.6.6 发布
20年编程,AI编程6个月,关于Copliot辅助编码工具,你想知道的都在这里
Java 8 内存管理原理解析及内存故障排查实践
消息队列选型之 Kafka vs RabbitMQ
从 MongoDB 到 PostgreSQL 的大迁移
腾讯云4月8日故障复盘及情况说明
PHP 在 2024 年还值得学习吗?
AMD集显安装显卡驱动之后出现黑屏,建议这样解决
使用 Docker 部署 moments 微信朋友圈 - 谱次· - 博客园
Java 17 是最常用的 Java LTS 版本
盘点Lombok的几个骚操作
Llama 3 + Ollama + Open WebUI打造本机强大GPT
如何优雅地编写缓存代码
Gmeek快速上手
笔记软件思源远程和本地接入大语言模型服务Ollama实现AI辅助写作(Windows篇)
Git Subtree:简单粗暴的多项目管理神器
这款轻量级规则引擎,真香!!
Ollama教程:本地LLM管理、WebUI对话、Python/Java客户端API应用
GLM-4-9B支持 Ollama 部署
智谱AI开源代码生成大模型第四代版本:CodeGeeX4-ALL-9B
美团二面:如何保证Redis与Mysql双写一致性?连续两个面试问到了!
免费开源好用,Obsidian和Omnivore真正实现一键联动剪藏文章,手把手教程!
得物 Redis 设计与实践
架构图怎么画?手把手教您,以生鲜电商为例剖析业务/应用/数据/技术架构图
使用Hutool要注意了!升级到6.0后你调用的所有方法都将报错 - 掘金
别再用雪花算法生成ID了!试试这个吧
无敌的Arthas!
Navicat Premium v16、v17 破解激活
🎉 分布式接口文档聚合,Solon 是怎么做的?
深入体验全新 Cursor AI IDE 后,说杀疯了真不为过!
Nacos 3.0 架构全景解读,AI 时代服务注册中心的演进
本文档使用 MrDoc 发布
-
+
Redis为什么能抗住10万并发?揭秘性能优越的背后原因
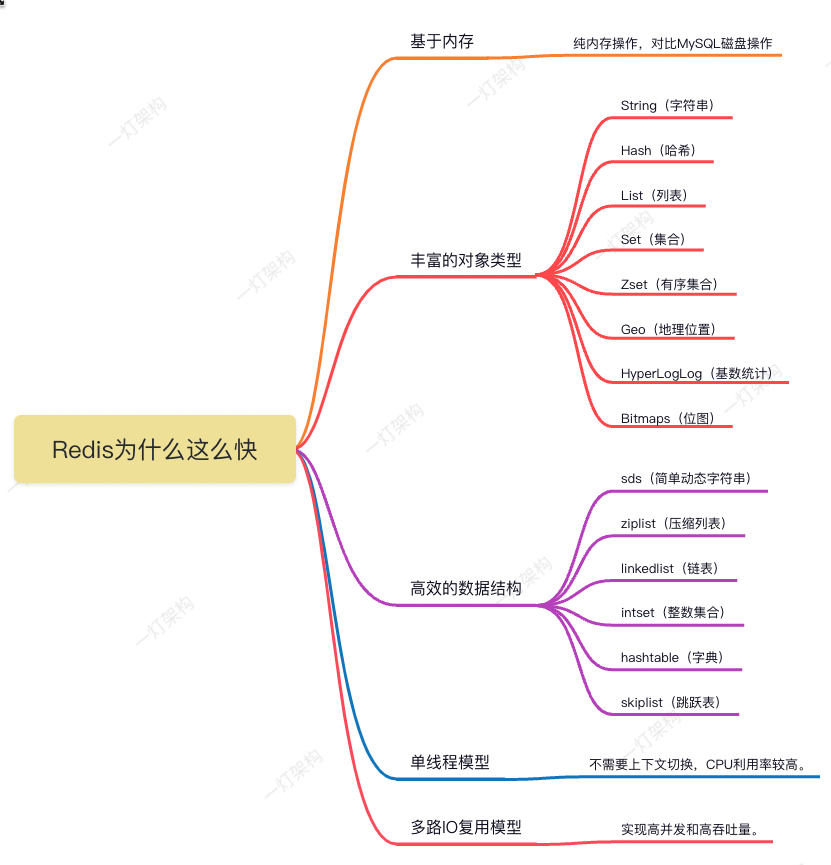 # 1\. Redis简介 Redis是一个开源的,基于内存的,高性能的键值型数据库。它支持多种数据结构,包含五种基本类型 String(字符串)、Hash(哈希)、List(列表)、Set(集合)、Zset(有序集合),和三种特殊类型 Geo(地理位置)、HyperLogLog(基数统计)、Bitmaps(位图),可以满足各种应用场景的需求。 Redis还提供了多种特性,如持久化、事务、发布订阅、Lua脚本、管道、主从复制、哨兵机制、集群机制等,可以保证数据的安全性、一致性和可用性。 Redis的速度非常快,官方称其可以达到每秒10万次的读写操作。和其他数据库相比,Redis有着明显的优势。例如,和MySQL相比,Redis的速度大约快了100倍;和MongoDB相比,Redis的速度大约快了10倍。这些优势使得Redis成为了很多互联网公司和开发者的首选数据库。 那么,Redis为什么这么快呢?主要有以下几个原因: - 使用内存存储数据,避免了磁盘IO的开销,提高了数据访问的速度。 - 丰富的对象类型,包含8种对象类型,满足不同场景的需求。 - 高效的数据结构,减少了内存占用和计算复杂度,提高了数据操作的效率。 - 单线程模型,避免了多线程之间的上下文切换和竞争条件,提升CPU利用率。 - 非阻塞IO多路复用机制,充分利用CPU和网络资源,提高了并发处理能力。 本文将详细介绍Redis为什么这么快的原理和机制,并给出一些实际应用和优化建议。 # 2\. 内存操作 Redis是一种基于内存的数据库,与传统的基于磁盘的数据库(例如MySQL)不同,它将所有的数据都存储在内存中。 那么,Redis为什么选择内存存储数据呢?主要有以下几个原因: 1. 内存的速度远远快于磁盘。内存读写速度可以达到每秒数百GB,而磁盘读写速度通常只有数十MB,万倍的差距。 2. 内存可以支持更多的数据结构和操作。常见的数据结构如数组、链表、树、哈希、集合等,常见的操作如排序、查找、过滤、聚合等。内存是一个灵活介质,满足各种复杂和高效的功能,不是磁盘操作可比的。 3. 内存可以支持更高的并发和扩展性。内存是一种分布式和并行的存储介质,它可以支持多个CPU核心同时访问同一块内存区域,也可以支持多个服务器之间共享同一块内存区域。磁盘是一种集中式和串行的存储介质,它只能支持一个CPU核心或一个服务器访问同一块磁盘区域,也不能支持多个服务器之间共享同一块磁盘区域。 当然,Redis使用内存存储数据也有一些缺点和限制: 1. 内存限制:内存是非常昂贵的,容量通常只有几十GB或几百GB,而磁盘目前都是TB起步。所以我们通常只会把少量的、经常访问的数据存储在内存中。 2. 数据类型限制:Redis不支持复杂的数据结构,比如用户对象,通常只能序列化成字符串后再存储,查询的时候再把字符串反序列化成用户对象。 3. 数据备份问题:在服务器重启或崩溃时,存储的内存中的数据可能会丢失。通常采用持久化技术将数据保存到磁盘上,同时定期备份数据以防止数据丢失。 # 3\. 丰富的对象类型 Redis包含五种基本类型 String(字符串)、Hash(哈希)、List(列表)、Set(集合)、Zset(有序集合),和三种特殊类型 Geo(地理位置)、HyperLogLog(基数统计)、Bitmaps(位图),可以满足各种应用场景的需求。 1. String可以用来做缓存、计数器、限流、分布式锁、分布式Session等。 2. Hash可以用来存储复杂对象。 3. List可以用来做消息队列、排行榜、计数器、最近访问记录等。 4. Set可以用来做标签系统、好友关系、共同好友、排名系统、订阅关系等。 5. Zset可以用来做排行榜、最近访问记录、计数器、好友关系等。 6. Geo可以用来做位置服务、物流配送、电商推荐、游戏地图等。 7. HyperLogLog可以用来做用户去重、网站UV统计、广告点击统计、分布式计算等。 8. Bitmaps可以用来做在线用户数统计、黑白名单统计、布隆过滤器等。 # 4\. 高效的数据结构 Redis有6种数据结构sds(简单动态字符串)、ziplist(压缩列表)、linkedlist(链表)、intset(整数集合)、hashtable(字典)、skiplist(跳跃表)。 Redis的8种对象类型底层都是基于这5种数据结构实现的,丰富的数据结构可以减少内存占用和计算复杂度,提高数据操作的效率。  # 5\. 单线程模型 Redis使用单线程模型,这意味着它只使用一个CPU来处理所有请求。因此,Redis不需要考虑多线程之间的同步、锁、竞争等问题,也不需要花费时间和资源在多线程之间的上下文切换上。这使得Redis的设计和实现更简单,性能和效率更高。 那么,Redis为什么选择单线程模型呢?主要有以下几个原因: 1. Redis性能瓶颈不在于CPU,而在于内存和网络。因为Redis使用内存存储数据,所以数据访问非常迅速,不会成为性能瓶颈。此外,Redis的数据操作大多数都是简单的键值对操作,不包含复杂计算和逻辑,因而CPU开销很小。相反,Redis的瓶颈在于内存的容量和网络的带宽,这些问题无法通过增加CPU核心来解决。 2. Redis的单线程模型可以保证数据的一致性和原子性。由于Redis只有一个线程来处理所有的请求,所以不会出现多个线程同时修改同一个数据的情况,也不需要使用锁或事务来保证数据的一致性和原子性。 3. Redis的单线程模型可以避免多线程编程的复杂性和难度。例如线程安全、死锁、内存泄漏、竞态条件等,降低了开发和维护的成本和风险。 # 6\. 多路IO复用模型 Redis使用单线程模型来处理客户端的请求,但是它能够利用多路I/O复用技术来实现高并发和高吞吐量。 那么,什么是多路I/O复用模型? 多路I/O复用模型是指使用一个线程来监控多个文件描述符(fd)的读写状态,当某个fd准备好执行读或写操作时,就通知相应的事件处理器来处理。这样就避免了阻塞式I/O模型中,单个线程只能等待一个fd的问题,提高了I/O效率和利用率。 例如Linux系统中提供了多种多路I/O复用技术的实现方式,如select、poll、epoll等。 # 7\. 总结 本文介绍了Redis为什么如此快的原因。 首先,Redis使用内存存储数据,避免了磁盘I/O的开销,提高了数据访问的速度。其次,Redis拥有丰富的对象类型,包含八种类型,满足不同的需求。此外,Redis采用了高效的数据结构,减少了内存占用和计算复杂度。Redis还使用单线程模型,避免了多线程之间的上下文切换和竞争条件,提升了CPU利用率。最后,Redis使用非阻塞I/O多路复用机制,充分利用CPU和网络资源,提高了并发处理能力。
admin
2023年4月15日 06:35
转发文档
收藏文档
上一篇
下一篇
手机扫码
复制链接
手机扫一扫转发分享
复制链接
Markdown文件
PDF文档(打印)
分享
链接
类型
密码
更新密码