IT博文
MySQL 事务隔离级别详解
使用 docker compose 安装 tidb
架构师日记-如何写的一手好代码
生产事故-记一次特殊的OOM排查
Docker安装RabbitMQ——基于docker-compose工具
使用 docker-compose 部署单机 RabbitMQ
只需3步,即刻体验Oracle Database 23c
长达 1.7 万字的 explain 关键字指南!
Redis为什么能抗住10万并发?揭秘性能优越的背后原因
深度剖析Redis九种数据结构实现原理
【绩效季】遇到一个好领导有多重要,从被打差绩效到收获成长
为什么Redis不直接使用C语言的字符串?
Java阻塞队列中的异类,SynchronousQueue底层实现原理剖析
如何调整和优化 Go 程序的内存管理方式?
应用部署引起上游服务抖动问题分析及优化实践方案
Java 并发工具合集 JUC 大爆发!!!
卷起来!!这才是 MySQL 事务 & MVCC 的真相。
JDK8 到 JDK17 有哪些吸引人的新特性?
告别StringUtil:使用Java 11的全新String API优化你的代码
从JDK8飞升到JDK17,再到未来的JDK21
Java JMH Benchmark Tutorial
linux和macOS下top命令区别
Windows10关闭Hyper-V的三种方法
为什么应该选择 POSTGRES?
阿里云对象存储 OSS 限流超过阈值自动关闭【防破产,保平安】
Java高并发革命!JDK19新特性——虚拟线程(Virtual Threads)
“请不要在虚拟机中运行此程序”的解决方案
Spring中的循环依赖及解决
浅谈复杂业务系统的架构设计 | 京东云技术团队
面试题:聊聊TCP的粘包、拆包以及解决方案
操作日志记录实现方式
字节跳动技术团队-慢 SQL 分析与优化
Spring Boot 使用 AOP 防止重复提交
Controller层代码就该这么写,简洁又优雅!
SpringBoot 项目 + JWT 完成用户登录、注册、鉴权
重复提交不再是问题!SpringBoot自定义注解+AOP巧妙解决
SpringBoot 整合 ES 实现 CRUD 操作
SpringBoot 整合 ES 进行各种高级查询搜索
SpringBoot操作ES进行各种高级查询
SpringBoot整合ES查询
如何做架构设计? | 京东云技术团队
最值得推荐的五个VPN软件(便宜+好用+稳定),靠谱的V2ray梯子工具
我说MySQL每张表最好不超过2000万数据,面试官让我回去等通知?
vivo 自研鲁班分布式 ID 服务实践
使用自带zookeeper超简单安装kafka
推荐 6 个很牛的 IDEA 插件
喜马拉雅 Redis 与 Pika 缓存使用军规
「程序员转型技术管理」必修的 10 个能力提升方向
jdk17 下 netty 导致堆内存疯涨原因排查 | 京东云技术团队
如何优雅做好项目管理?
MySQL 到 TiDB:Hive Metastore 横向扩展之路
聊聊即将到来的 MySQL5.7 停服事件
Linux终端环境配置
微软 Edge 浏览器隐藏功能一览:多线程下载、IE 模式、阻止视频自动播放等
Hutool 中那些常用的工具类和实用方法
clash 内核删库?汇总目前常用的内核仓库和客户端
JDK11 升级 JDK17 最全实践干货来了 | 京东云技术团队
我是如何写一篇技术文的?
虚拟线程原理及性能分析
Java线程池实现原理及其在美团业务中的实践
Editplus和EmEditor配置一键编译java运行环境
用Spring Boot 3.2虚拟线程搭建静态文件服务器有多快?
SpringBoot中使用LocalDateTime踩坑记录 - 程序员偏安 - 博客园
程序员必备!10款实用便捷的Git可视化管理工具 - 追逐时光者 - 博客园
基于Netty开发轻量级RPC框架
开发Java应用时如何用好Log
复杂SQL治理实践 | 京东物流技术团队
火山引擎ByteHouse:分析型数据库如何设计并发控制?
多次崩了之后,阿里云终于改了
推荐程序员必知的四大神级学习网站
初探分布式链路追踪
新项目为什么决定用 JDK 17了
Java上进了,JDK21 要来了,并发编程再也不是噩梦了
mapstruct这么用,同事也开始模仿
再见RestTemplate,Spring 6.1新特性:RestClient 了解一下!
【MySQL】MySQL表设计的经验(建议收藏)
如何正确地理解应用架构并开发
解读工行专利CN112905176B
工商银行取得「基于 Spring Boot 的 web 系统后端实现方法及装置」专利
IDEA 2024.1:Spring支持增强、GitHub Action支持增强、更新HTTP Client等
TIOBE 2 月:Go 首次进入前十、“上古语言” COBOL 和 Fortran 排名飙升
Java 21 虚拟线程如何限流控制吞吐量
🎉 通用、灵活、高性能分布式 ID 生成器 | CosId 2.6.6 发布
20年编程,AI编程6个月,关于Copliot辅助编码工具,你想知道的都在这里
Java 8 内存管理原理解析及内存故障排查实践
消息队列选型之 Kafka vs RabbitMQ
从 MongoDB 到 PostgreSQL 的大迁移
腾讯云4月8日故障复盘及情况说明
PHP 在 2024 年还值得学习吗?
AMD集显安装显卡驱动之后出现黑屏,建议这样解决
使用 Docker 部署 moments 微信朋友圈 - 谱次· - 博客园
Java 17 是最常用的 Java LTS 版本
盘点Lombok的几个骚操作
Llama 3 + Ollama + Open WebUI打造本机强大GPT
如何优雅地编写缓存代码
Gmeek快速上手
笔记软件思源远程和本地接入大语言模型服务Ollama实现AI辅助写作(Windows篇)
Git Subtree:简单粗暴的多项目管理神器
这款轻量级规则引擎,真香!!
Ollama教程:本地LLM管理、WebUI对话、Python/Java客户端API应用
GLM-4-9B支持 Ollama 部署
智谱AI开源代码生成大模型第四代版本:CodeGeeX4-ALL-9B
美团二面:如何保证Redis与Mysql双写一致性?连续两个面试问到了!
免费开源好用,Obsidian和Omnivore真正实现一键联动剪藏文章,手把手教程!
得物 Redis 设计与实践
架构图怎么画?手把手教您,以生鲜电商为例剖析业务/应用/数据/技术架构图
使用Hutool要注意了!升级到6.0后你调用的所有方法都将报错 - 掘金
别再用雪花算法生成ID了!试试这个吧
无敌的Arthas!
Navicat Premium v16、v17 破解激活
🎉 分布式接口文档聚合,Solon 是怎么做的?
深入体验全新 Cursor AI IDE 后,说杀疯了真不为过!
Nacos 3.0 架构全景解读,AI 时代服务注册中心的演进
本文档使用 MrDoc 发布
-
+
别再用雪花算法生成ID了!试试这个吧
大家好啊,我是码财同行。今天继续聊服务器中唯一ID生成。唯一ID生成中雪花算法大家都比较熟,那如果加一个要求呢: > 尽量短的数字ID  ## 背景 之前的项目有个需求:为用户账号生成账号ID。最开始用的是UUID(长字符串ID),但是字符串账号相对于数字账号,存储和传输性能都稍逊,也不利于记忆和传播。 因此,生成一套业务内的数字账号,并且尽量简短就是当务之急。 ## 初步版本 我们最开始考虑的是雪花算法方案,使用的是经典的 twitter开源的算法 snowflake。这个算法非常强大,生成的是 64bit 的数字id,天然支持分布式。 有关这个算法的详细分析,可以查看我前一段时间发的这篇文章:[【收藏级】唯一ID生成探讨:论ID与猪肉?](https://juejin.cn/post/7386243179278041128) 雪花算法看起来无懈可击,但是唯一的问题就是生成的64位 ID 太长了。账号ID希望能控制的尽量短,个人理解有以下原因: - 账号id一般显示在个人设置里,会暴露给用户,需要便于输入 + 记忆,这样客服查询起来更方便; - 账号id短并且有序能提高账号库的写入性能; 于是着手改进。 ## 改进版本 一个比较可行的方案是利用数据库的自增 ID 特性。 为了便于理解,我们先来看一下业务里的账号登录流程: - 客户端上传第三方openid及token来登录,登录服拿到openid后需要查询是否已经注册账号 - 如果能查到账号ID,表明已经注册,再根据查到的数字账号来做后续登录逻辑 - 如果查不到,则需要新注册一个账号到账号表 - 新建账号首先需要生成一个数字的账号ID,在目前的机制中,通过一张专门的`ID生成表`来做的。 OK,先来看我们如何在mysql中存储账号相关信息的: - **账号表**,accid就是我们说的数字账号。考虑到账号数量级可能到千万甚至上亿,单表的性能肯定不理想,因此我们分了10张表。其表结构为 ```sql CREATE TABLE `tbl_global_user_map_00` ( `account` varchar(32) NOT NULL, `accid` bigint(20) NOT NULL, `created_at` datetime DEFAULT NULL, PRIMARY KEY (`account`) USING BTREE ) ENGINE=InnoDB DEFAULT CHARSET=utf8 ``` - **账号ID生成表**,其表结构为 ```sql CREATE TABLE `tbl_accid` ( `id` bigint(20) NOT NULL AUTO_INCREMENT, `stub` char(1) NOT NULL DEFAULT '', PRIMARY KEY (`id`) USING BTREE, UNIQUE KEY `UQE_tbl_accid_stub` (`stub`) USING BTREE ) ENGINE=InnoDB DEFAULT CHARSET=utf8 ``` 数据为  整个表只有一行数据,id列为自增列,它的值就是最新生成的账号ID值。这个ID生成的原理是: - 设置id列为自增,这样每插入一列id值就会自动递增 - 如果没有其他限制,这张表的数据就会随着insert的次数越来越多,假如账号有几千万,这张表就有几千万行数据 - 为此,我们增加了一列 stub,设置其为 unique key,并且每次insert其值都是一样的(例如设置为 'a'),这样就保证整个表只有一行数据,而id会随着每次insert自动递增。 - 如果直接用 insert into 语句来做插入,肯定每次都返回错误(除了第1次),因为 stub 为 ‘a’ 的记录已经存在了,每次插入都会失败。 - 我们改用 MySQL 扩展的 SQL 语句 replace into 来实现。replace 必须要配合唯一索引来使用。 于是 SQL 语句就是 ```scss REPLACE INTO tbl_accid(`stub`) VALUES('a'); ``` 它的效果如下: - 如果 stub 为 'a' 的记录不存在,则插入,类似 insert 操作 - 如果 stub 为 'a' 的记录已经存在,则先 delete 该条记录,再 insert 新记录。由于删除已有的记录时,表的自增值不会变化,再新增记录时 id 会在老的自增值基础上继续递增 **有同学可能要问了,为什么要搞一个单独的`ID生成表`来生成自增id?将自增字段直接放到账号表中不行么?** 关键的问题在于`业务要分表`。假如账号表分了10张,要合并自增id列的话,需要划分好每张表的生成范围。 例如我们设计每张表可以生成 100w 个id,那 10 张表的起始id 分别是 1, 1000001,2000001, ... 跨度非常大,和我们当初的设计:简短并尽量连续的要求违背。 因此,专门的账号ID生成表是必要的。 ## 问题暴露 上述方案完成之后,我就去吃火锅唱歌去了。  然后,就出现了一个比较棘手的问题。某天晚上QA同事反馈压力测试有报错,登录服会间歇性返回db错误,如下: ```vbnet ERROR : Deadlock found when trying to get lock; try restarting transaction ``` 登录服收到该返回后打印了错误日志,提示客户端服务器发生错误。很明显,这个方案有死锁问题。  google了一下 replace 在并发情况下的死锁问题,大致和 replace 被分解成 delete + insert 有关,而 innodb又是行锁机制。详细的原因非常复杂,有关资料为 [yq.aliyun.com/articles/41…](https://link.juejin.cn?target=https%3A%2F%2Fyq.aliyun.com%2Farticles%2F41190) [techlog.cn/article/lis…](https://link.juejin.cn?target=https%3A%2F%2Ftechlog.cn%2Farticle%2Flist%2F10183451%23l) [blog.itpub.net/7728585/vie…](https://link.juejin.cn?target=http%3A%2F%2Fblog.itpub.net%2F7728585%2Fviewspace-2141409%2F) 很多博客也给出了建议: > 通过几个死锁案例,我们强烈建议在生产环境中尽量避免使用REPLACE INTO和INSERT INTO ON DUPLICATE UPDATE语句,改用普通INSERT操作,并对INSER操作部分代码加入异常加查,当INSERT失败时改为UPDATE操作。 为了再验证一次死锁的并非语言或者API的bug,我用了 mysql 自带的压测工具 mysqlslap 做了个简单测试: ```css mysqlslap -uroot -p --create-schema="db_global_200" --concurrency=2 --iterations=5 --number-of-queries=500 --query="replace_innodb.sql" mysqlslap: Cannot run query REPLACE INTO tbl_yptest_innodb(`stub`) VALUES('a'); ERROR : Deadlock found when trying to get lock; try restarting transaction ``` 结果显示并发数为 2 时就出现了死锁问题。然后我又尝试将表引擎改为 myisam,再次压测,虽然没有出现死锁问题,但是MYISAM引擎更新数据的效率比较低。因此我们不得不放弃了mysql自增ID的方案,再想其他方案。  ## 其他方案1 继续尝试其他方案。其实,我们最新的ID生成方案参考了美团技术团队的一篇文章,有兴趣的可以查阅:[Leaf——美团点评分布式ID生成系统](https://link.juejin.cn?target=https%3A%2F%2Ftech.meituan.com%2F2017%2F04%2F21%2Fmt-leaf.html) 文中提到了一种Flickr团队的改进方案: 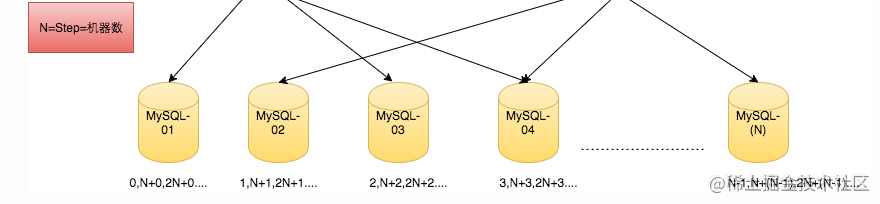 即:使用 N 个mysqlserver,来提高可用性,降低每个 mysqlserver的压力和并发数。如果 replace into 不支持并发,那就部署尽可能多的 mysqlserver,每次 replace into 时串行。 然而这种方式部署限制和消耗都太大,而且我们的登录服是多开的,即使在单登录服内控制串行,多个进程也不好控制,因此这个初始的方案只能被pass。 回到开始的思路,能不能将自增id合并到 账号表\_xx 中,从而放弃 replace 呢? 我们可以将每个 tbl\_global\_user\_map 分表类比成上图中的 mysql-01, mysql-02, ... 然后自增时,采取 **间隔步长N** 的方式(默认的自增步长是1,每次自增加1) 举例: tbl\_global\_user\_map\_00 表,起始id 20000,每次加10,其生成的 id 每次是 20000, 20010, 20020, 20030... tbl\_global\_user\_map\_01 表,起始id 20001,也是每次加10,其生成的 id 每次是 20001, 20011, 20021, 20031... ... 这个id看起来间隔很小,看起来非常理想。 需要做的事情就是设置 auto\_increment\_increment 和 auto\_increment\_offset 两个mysql中的变量。 然后很可惜,这两个变量属于 全局 或者 session(连接会话) 级别,没有 table 级别的设置。 如果我们设置了这两个变量,很容易影响其他表,产生其他错误。 ## 其他方案2 再想其他方案。 仔细整理一下我们的需求,就会发现我们的账号表一般只有新增,没有删除和修改。能不能利用`读写分离`的思想,在插入新映射关系(同时生成自增账号ID)时,只有一张表可写,自增id可以每次只加1;而查询时,属于读,读的数据可以分布在10张表中。我们要做的就是定期将可写表中已有的一些数据迁移到只读的这10张表中(根据账号ID做shard),控制可写表的数量级不能太大。 账号ID在写表中自增,相当于自动分配账号ID。  这个机制有点类似于我们的`日志滚动`,当前正在写的日志文件不停被写入(插入日志),当超过一定大小或者日期切换时会滚动成只读的文件。 **这个方案理论上可行,但是有运维复杂性**:需要配合运维来做数据迁移,维护成本比较高,因此组内讨论后我们决定pass掉。 ## 其他方案3(最终方案) 我之前所在的成熟项目也用过上述【其他方案1】中类似美团的方案,即`预申请一批ID`的方式。 对比来看,我们之前申请ID都是一次自增1,而这种预申请一批的方式,是一次申请N个ID,自增N,可以减少请求量和并发。当请求量明显下降后,之前方案里担忧的问题:ID生成表插入行数过多也就不存在了。 `唯一的问题是:预申请的ID可能会被浪费`。如果申请了一段区间的id,但是没有用完,服务器停服再启动后会再申请一段新的,原来未使用的ID就被浪费了。 因此我们着手优化这种算法,目的很明显: > 减少浪费的ID,去除空洞号段,并自动兼容登录服扩容与容灾的情况。 如果这个目的能达成,那就完美契合了我们当初的需求。  ## 短ID方案细节 设计发号表 tbl\_account\_freeid | 号段编号,自增 | svr编号 | 号段内剩余freeid数量 | | --- | --- | --- | | segment | loginsvr | left | 每个登陆服要申请一批账号ID时,就来表中插入一行,规定每次申请1000个,由于segment自增,相当于申请了 \[(segment - 1) \* 1000, segment \* 1000) 这段区间,申请时候默认 left 是 0 登录服正常停服维护时将剩余未用完的数量写入 left,防止浪费,下次启动时候还可以再利用。 以下分析各种case: a) 初始 tbl\_account\_freeid 没有数据,假如 loginsvr 开3个实例,实例编号分别是1,2,3。 服务器启动时候需要做一次查找,要找对应 实例编号的segment。如果找到了,且 left 不为 0,则说明该号段还可以用;如果找不到,或者left为0,则需要新申请(新插入一行记录)。 于是第一次启服后数据为 | 号段编号,自增 | svr编号 | 号段内剩余freeid数量 | | | --- | --- | --- | --- | | segment | loginsvr | left | | | 1 | 2 | 0 | 内存中号段为 1-1000 | | 2 | 1 | 0 | 内存中号段为1001-2000 | | 3 | 3 | 0 | 内存中号段为2001-3000 | b) 如果loginsvr发现内存中号段用完了,就不用再查找,直接申请,往数据库插入一行数据,假定实例编号 1 和 3 的 号段用完了,新申请。 然后各个登录服正常停服,left 回写。可能的数据情况如下: | 号段编号,自增 | svr编号 | 号段内剩余freeid数量 | | | --- | --- | --- | --- | | segment | loginsvr | left | | | 1 | 2 | 200 | | | 2 | 1 | 0 | (使用完毕,该行可删) | | 3 | 3 | 0 | (使用完毕,该行可删) | | 4 | 1 | 800 | | | 5 | 3 | 750 | | c) 再次起服时,查找到各个编号的实例都有号段可用。无需新插入数据,但是对应的 left 要改为0(相当于申请了 left 个) | 号段编号,自增 | svr编号 | 号段内剩余freeid数量 | | | --- | --- | --- | --- | | segment | loginsvr | left | | | 1 | 2 | 0 | 登录服内存中号段为 801-1000(剩余的200个) | | 2 | 1 | 0 | (使用完毕,该行可删除) | | 3 | 3 | 0 | (使用完毕,该行可删除) | | 4 | 1 | 0 | 登录服内存中号段为3201-4000(剩余的800个) | | 5 | 3 | 0 | 登录服内存中号段为4251-5000 (剩余的750个) | d) 如果此时 loginsvr 扩容,新增编号 4 - 10 的 svr,和初始情况类似,需要先查找,没有则申请。此时数据可能为 | 号段编号,自增 | svr编号 | 号段内剩余freeid数量 | | | --- | --- | --- | --- | | segment | loginsvr | left | | | 1 | 2 | 0 | 登录服内存中号段为 801-1000(剩余的200个) | | 2 | 1 | 0 | (使用完毕,该行可删除) | | 3 | 3 | 0 | (使用完毕,该行可删除) | | 4 | 1 | 0 | 登录服内存中号段为3201-4000(剩余的800个) | | 5 | 3 | 0 | 登录服内存中号段为4251-5000 (剩余的750个) | | 6 | 4 | 0 | 登录服内存中号段为5001-6000 | | 7 | 5 | 0 | 登录服内存中号段为6001-7000 | | 8 | 6 | 0 | 登录服内存中号段为7001-8000 | | 9 | 7 | 0 | 登录服内存中号段为8001-9000 | | 10 | 8 | 0 | 登录服内存中号段为9001-10000 | | 11 | 9 | 0 | 登录服内存中号段为10001-11000 | | 12 | 10 | 0 | 登录服内存中号段为11001-12000 | 这种方式的特点就是,登录服服务过程中,对应数据库里的 left 为 0,如果停了,数据库里 left 为号段内剩余的可用数量。 如果登录服宕机,则没有回写 left 的过程,则对应号段内没有用完的(最多1000)会浪费。 ## 结尾 以上就是我们在账号短ID生成上的探索,最终方案经历了长时间的生产环境的测试,运转正常。如果小伙伴们有更优秀的经验欢迎一起交流。 好了,看了这么多,一定很费脑力吧。来个笑话放松一下 :) > 【笑话一则】喝多了准备打车回家,本来想叫嘀嘀打车,结果叫成了滴滴代驾。等代驾到了,我们对视了10秒,异口同声得说:“你车呢?” 感谢您花时间阅读这篇文章!如果觉得有趣或有收获,请来个关注、评论、点赞吧,您的鼓励是我持续创作的动力,蟹蟹! 
admin
2024年7月26日 22:54
转发文档
收藏文档
上一篇
下一篇
手机扫码
复制链接
手机扫一扫转发分享
复制链接
Markdown文件
PDF文档(打印)
分享
链接
类型
密码
更新密码